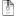I am working on a security platform called "remedium" and would like to share it with the community at reboot. This platform hosts different applications that expose and prevent malicious activities.
If you have some time to help with feedback, I would be deeply grateful..

This is the initial beta, at this moment you can only see two demonstrations of the sentinel application in place:
- Index all files inside your computer
- Immunize USB flash drives when inserted in the computer
Below is a screenshot of remedium in action.

Remedium works across Windows, Linux (tested in Ubuntu) and MacOSX. I am including the .exe file that can be run directly from explorer. For other operative systems you should launch the executable from command line using "java -jar remedium.exe".
When launching from command line you get access to the log messages, please use the command line when testing remedium.
On this test you should be able of completing the index process. If some problem is output on the log, please do let me know on this topic.
You can download the binary from http://remedium.googlecode.com
-----------
The indexing of files allows to create a database of files that are found on your machine. In the future, it is intended that this information can be merged with the information from other workstations on a given network. The idea is to assign a score on files that are considered of trust or not.
After enough information is gathered, we can run metrics on the collected information. For example, if a kernel32.dll file is modified by a malicious process, we should be able of detecting that no similar file from Microsoft existed before and that this be treated as a suspicious event (more details on this algorithm will be explained later).
Thank you for helping!

Attached Files
-
 remedium_sentinel_110622-JUN.png 300.45KB
3 downloads
remedium_sentinel_110622-JUN.png 300.45KB
3 downloads