Yes and no. (as always)  .
.
Copying to ramdisk is a possibility, but only useful for smallish files (the ones where slowness is not an issue) but unfeasible for large transfers.
I thought a bit around the matter, and we can get away with a couple abstractions and a "mixed" approach[1]. 
There are two possibilities for the objects that are the if and of in dd:
1) a single blocklist or a contiguous file that can be directly translated to a single blocklist
2) a non-contiguous file (or multiple blocklist)
There are two possibilities for bs:
1) a power of 2 smaller than 512 bytes, i.e. 1, 2, 4, 8, 16, 32, 64, 128, 256
2) a power of 2 equal to or bigger than 512
In case #2 of bs the skip and/or seek can only be multiples of 512 and thus can be managed at block level.
In case #1 of bs the skip and/or seek can only affect 1 or 2 blocks (the first and last block of the bytes transferred), let's call these areas conventionally "head" and "tail" respectively, and the *whatever* is between these two areas "body".
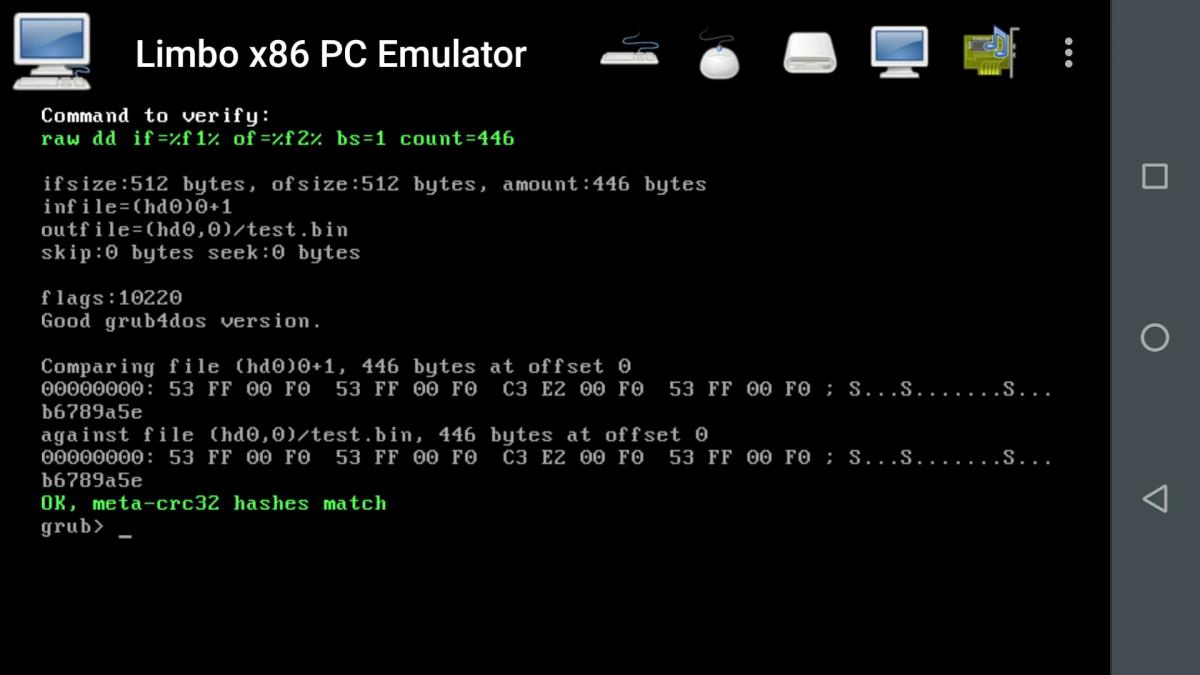
The "head" can be only anything between 1 and 511 bytes and can be dealt with the crc32 of 16 bytes at the time[2], the whatever* comes after starts on a block (512 bytes) border and can be dealt at block level.
Same for the "tail", with the advantage that - accessed at block level - we can use the crc32 "comma" trick for it.
So, in case of contiguos files or blocklists we will have at most three crc32's.
The issue than becomes another one, the body of: fragmented files. 
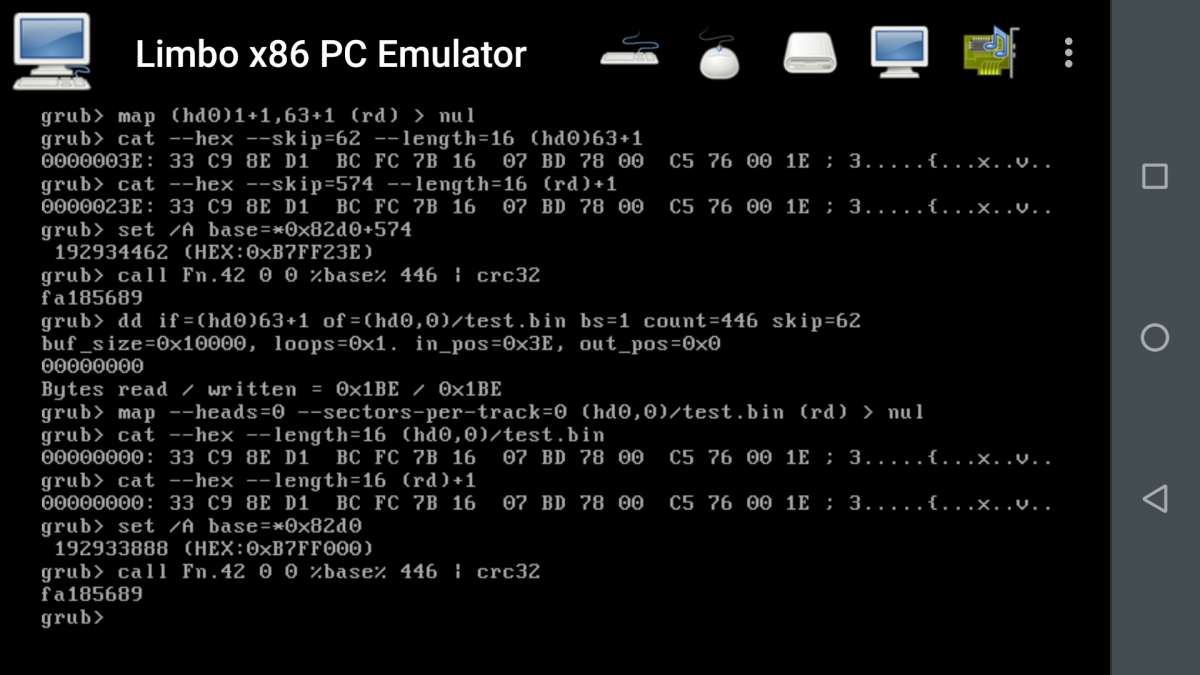
A file accessed through the filesystem (i.e. (device)/file.ext) is "virtually" contiguous and the crc has no issues with it, but you cannot access it via blocklist as you don't have a single blocklist, but rather a number of blocklists.
The challenge is to create a way to "dissect" a non-contiguous file into a list of the single blocks that compose it, than crc32 each of them.
In this latter case we will have instead of 3 crc32's, 1+n+1 of them.
But we can still put all of them into a string variable and then crc32 the string, the resulting crc32 is not anymore a crc32, but rather a meta-crc32, that anyway can be compared to another meta-crc32 built in the same way.
The limit then becomes how many crc32's can fit into a string variable, as each of them represents a block of the transferred files, since the limit for a variable is 512 bytes, it can store 512/4=128 blocks worth of crc32's, which is a rather smallish file.
BUT we can still use a progressive crc32 approach, i.e. calculate the crc32 of the string set crc32tillnow=<crc32tillnow><crc32ofthisblock>, it might be a meta-meta crc32, but as long as the comparison term is calculated in the same way the comparison is valid.
I invented a crazy flags system to distinguish possible cases (and to adopt the faster strategy for each of them), if my calculations are correct  there are 108 possible cases that can be grouped into (I don't actually know, rough guesstimate) 6-8 groups, maybe less due to some symmetries, for the moment I identified 3 groups and "solved" only the first two (the actually easy ones
there are 108 possible cases that can be grouped into (I don't actually know, rough guesstimate) 6-8 groups, maybe less due to some symmetries, for the moment I identified 3 groups and "solved" only the first two (the actually easy ones  ).
).
I am attaching (only FYI, very little practical use, covers - maybe - 9 cases out of 108) the "skeleton".

Wonko
[1] I am working on a basic implementation of it, in theory it may work, in practice it has to be seen.
[2] either directly or copying the partial block to ramdisk, but, since we have at most one single block (sector) to deal with, nothing prevents us from:
a. zeroing a sector in memory
b. copying to it the "head" bytes
c. calculate the crc32 of the "whole" sectors, 00's included <- this will be a sort of "virtual" (besides partial) crc32, but as long as this "virtual" source head matches the corresponding as well "virtual" destination head, the verification is done correctly





 idd_v04.zip 4.56KB
484 downloads
idd_v04.zip 4.56KB
484 downloads


 instead of verifying by comparing, use crc32 for hash verifying, then when I find (please read as "you tell me") how to update properly the command history buffer, the batch could push to it:
instead of verifying by comparing, use crc32 for hash verifying, then when I find (please read as "you tell me") how to update properly the command history buffer, the batch could push to it:



 a 6 , i.e. can we get away with this added to the beginning of the sub?
a 6 , i.e. can we get away with this added to the beginning of the sub? 




 , though in this particular case I actually "like" this 1 second pause, it looks like the program is actually needing to do something profound and complex
, though in this particular case I actually "like" this 1 second pause, it looks like the program is actually needing to do something profound and complex 




 so maybe I am too pessimistic.
so maybe I am too pessimistic.